Ensuring Fair Play: An Exploration of Bias Mitigation Methodologies across the lifecycle of a Machine Learning Model
Our project “Ensuring Fairplay” is dedicated to addressing the pervasive issue of bias in machine learning (ML) systems. As ML models are increasingly deployed in high-stakes domains—such as healthcare, finance, hiring, and criminal justice—unmitigated biases can lead to discriminatory outcomes that perpetuate historical inequities. We aim to identify, quantify, and mitigate these biases at multiple stages of the ML pipeline, ensuring that our predictive models deliver equitable outcomes across diverse subgroups. In essence, our goal is to transform ML models into fair decision-makers that do not disadvantage marginalized or underrepresented populations.
PROJECTS
5/8/20245 min read

Motivation:
The ubiquity in the utilisation of Machine Learning models to aid in making critical decisions across multiple sectors such as banking, insurance, hiring, and prison sentencing has placed a significant emphasis on ensuring fairness in AI models. In an era that has been defined by exponential acceleration of this new technology, it is important to anticipate and mitigate any potential bias that may arise in a given system. However, this has proven to be a pertinent problem, given that the biases that are found in the real world often permeate into the datasets used to train ML models. This in turn creates a situation where biases and prejudices prevalent in society are exacerbated by the algorithm. This project aims to mitigate the biases in the data and the ML Model at various points in the development lifecycle of the model.
Relevance of Fairness:
Fairness in ML is not just an ethical imperative—it is essential for maintaining public trust and ensuring legal compliance. Bias in AI can lead to unjust resource allocation, such as unequal access to healthcare services, and reinforce societal inequalities. Our work emphasizes that fair algorithms must not only achieve high overall accuracy but also perform equitably across all demographic groups. By integrating fairness into the model development lifecycle, we aim to reduce discrimination and create AI systems that promote social justice and equal opportunity.
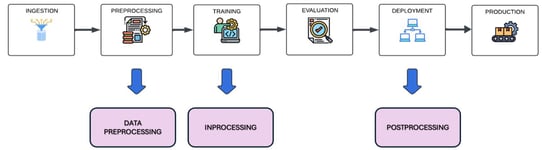
Bias in the ML Pipeline
Bias can infiltrate ML models at every stage—from data collection and feature selection to training and deployment.
Data Collection & Preparation: Historical inequities, unrepresentative sampling, and poor data quality can embed biases in the raw data.
Feature Engineering: The selection and transformation of features may inadvertently capture sensitive attributes, thereby introducing or amplifying bias.
Model Training: Standard optimization processes tend to focus on overall accuracy, sometimes at the expense of fairness, which may result in disparate outcomes across subgroups.
Evaluation & Deployment: Even when a model performs well on aggregate metrics, it can still produce biased predictions for specific populations if not properly assessed using fairness metrics.
Our project addresses these challenges by implementing bias detection and mitigation strategies at the preprocessing, in-processing, and post-processing stages of the ML pipeline.
Dataset Description (MEPS):
We leverage the Medical Expenditure Panel Survey (MEPS) dataset—a comprehensive, nationally representative survey that captures detailed healthcare information for the non-institutionalized U.S. population.
Scope & Content: The MEPS dataset provides crucial insights into healthcare usage, costs, and insurance coverage, along with extensive demographic and health-related variables.
Data Pruning: For our analysis, we selected a relevant subset of 44 columns that include key demographic attributes (such as race, age, gender, and region) and health indicators (including Physical Component Summary (PCS42), Mental Component Summary (MCS42), and a newly derived “utilization” score that aggregates healthcare service usage).
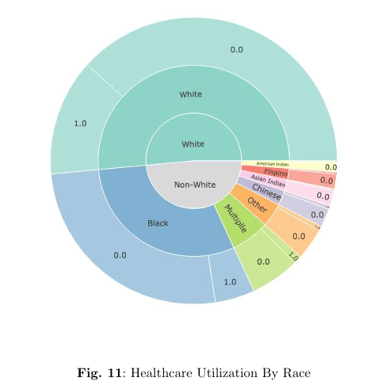
Sensitive Attributes: In this study, “Race” is treated as the sensitive attribute, allowing us to evaluate and mitigate bias across racial groups.
Bias Detection Strategy
To rigorously assess fairness, we apply a suite of statistical tests and metrics:
Statistical Parity Difference: Measures the difference in the rate of favorable outcomes between privileged and unprivileged groups.
Equal Opportunity Difference: Evaluates the disparity in true positive rates across these groups.
Average Absolute Odds Difference: Provides a balanced view of discrepancies in both false positive and true positive rates.
Disparate Impact: Examines the ratio of favorable outcomes between groups, with a value of 1 indicating parity.
Theil Index: Quantifies the inequality in the distribution of model predictions.
These metrics collectively offer a comprehensive view of bias in the base model, guiding the subsequent mitigation efforts.
Bias Mitigation Strategy
Our project employs a multi-pronged approach to mitigate bias throughout the ML pipeline:
Preprocessing Techniques:
Reweighing: Adjusts instance weights to balance the influence of underrepresented groups in the training data.
Disparate Impact Remover: Modifies feature values to harmonize distributions across groups without altering the inherent data structure.
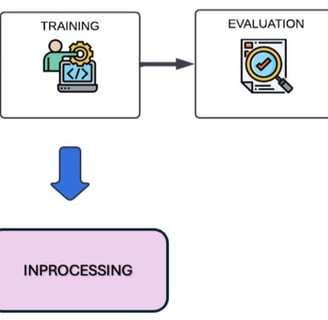
In-Processing Techniques:
Prejudice Remover: Incorporates a fairness-aware regularizer into the model’s objective function to penalize reliance on sensitive attributes.
Adversarial Debiasing: Utilizes adversarial networks that compete to remove sensitive information from the learned representations during model training.
Post-Processing Techniques:
Methods like Equalized Odds Postprocessing and Reject Option Classification are used to adjust model predictions after training, ensuring that the final outputs meet fairness criteria.
Novel Methodology
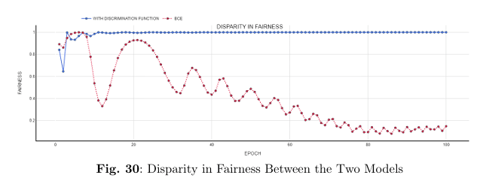
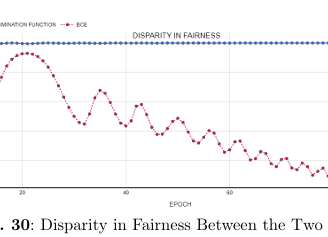
A key innovation in our project is the development of a Discrimination-Aware Loss Function. This novel in-processing strategy integrates fairness directly into the model training phase by modifying the conventional loss function.
Custom Loss Formulation:
The new loss function combines standard Binary Cross-Entropy (BCE) with an additional discrimination term that penalizes discrepancies in the probabilities of positive outcomes between privileged and unprivileged groups.Hyperparameters (λ and k):
The strength of the fairness penalty is controlled by hyperparameters λ (lambda) and k. Adjusting these parameters allows us to fine-tune the balance between reducing discrimination and preserving overall model accuracy.Impact:
Experimental results show that models trained with the discrimination-aware loss function rapidly converge to near-zero discrimination levels while maintaining competitive accuracy, outperforming conventional bias mitigation methods.
Results
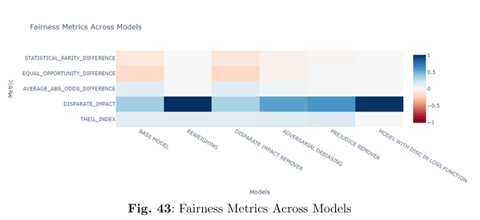
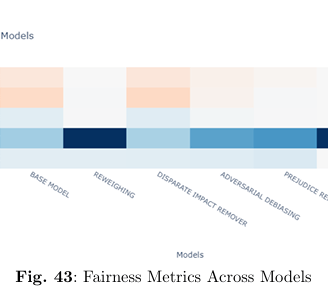
Our comprehensive evaluation compares various bias mitigation strategies using the MEPS dataset:
Baseline Model:
The initial logistic regression model exhibits noticeable bias across racial groups, as indicated by non-zero fairness metrics (e.g., a Statistical Parity Difference of -0.12 and a Disparate Impact value of 0.35).Mitigation Strategies Comparison:
Reweighing: Achieves significant improvements, with fairness metrics approaching ideal values (e.g., Statistical Parity Difference and Equal Opportunity Difference near 0.00, and Disparate Impact around 1.01).
Disparate Impact Remover & Prejudice Remover: Although these methods improve fairness, they often incur trade-offs in recall and specificity.
Adversarial Debiasing: Offers moderate enhancements in fairness but still leaves some imbalances.
Novel Discrimination-Aware Loss Function:
The standout method, our novel loss function, delivers exemplary fairness—achieving perfect or near-perfect scores (all fairness metrics reaching 0.00 or 1.00 as appropriate) without sacrificing overall predictive performance.
For more results of our Novel method, click here: https://srinivassundar98.github.io/Ensuring-Fair-Play/FinalDisc_LossFunction.html
The code for this project can be found at: https://github.com/srinivassundar98/Ensuring-Fair-Play
The report for the project can be found here: https://github.com/srinivassundar98/Ensuring-Fair-Play-FDM-Project/blob/main/Ensuring%20Fair%20Play%20FDM.pdf