From Prompt to Pipeline: Building an AI-Powered Data Analysis Framework
Transforming natural language requests into complete data analysis pipelines with AI
PROJECTS
Srinivas Sundar
5/10/20256 min read
Introduction
In today's data-driven world, the ability to quickly extract insights from datasets is crucial. However, the traditional data analysis workflow often involves multiple steps: data ingestion, cleaning, transformation, visualization, and storytelling. Each step typically requires expertise in different tools and programming languages, creating a barrier for those without specialized skills.
What if we could simplify this entire process? What if you could simply describe what you want to analyze, and an AI would handle the rest? That's exactly what I've built with the Prompt-to-Pipeline framework.
What is Prompt-to-Pipeline?
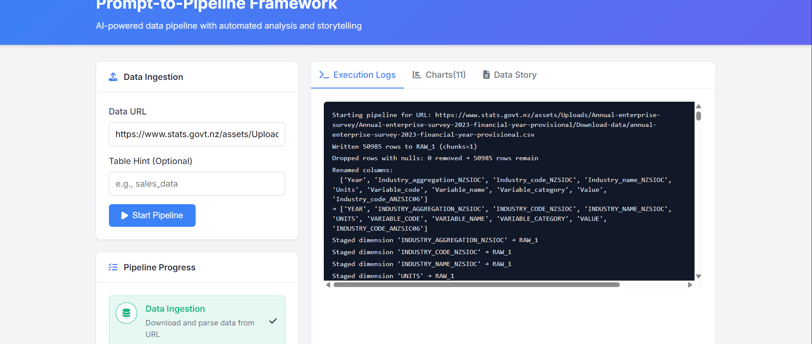
Prompt-to-Pipeline is an AI-powered data analysis framework that converts natural language requests into complete data analysis pipelines. With a simple text prompt and a data source URL, the system will:
Ingest your data from any URL (CSV, Parquet, etc.)
Clean and transform the data automatically
Analyze and visualize key insights
Generate a narrative story explaining what was discovered
The entire process is driven by AI, which means you don't need to write a single line of code. Just provide a URL to your dataset and watch as the pipeline unfolds.
The Architecture: A Deep Dive into a Modern Reactive Data Pipeline
The Prompt-to-Pipeline framework represents a convergence of modern data engineering practices and AI agent methodologies. Let's explore the sophisticated architecture that enables this system to function as a cohesive whole.
Reactive Event-Based Processing Model
At its core, the pipeline implements a reactive event processing model. Rather than sequential execution, components communicate through a well-defined event system that enables loose coupling while maintaining data consistency. This approach allows for:
Horizontal Scalability: Components can be scaled independently based on load
Fault Tolerance: Failures in one component don't cascade to others
Extensibility: New components can be added without redesigning the system
The framework leverages Python's threading model for concurrent execution while maintaining a unified state across the pipeline. This allows multiple operations to happen simultaneously without blocking the main thread—critical for handling large datasets while keeping the UI responsive.
Component Architecture: Beyond Simple Microservices
The system's components are designed as autonomous modules with distinct responsibilities, but they share context and state through a carefully designed API surface. This hybrid approach provides the benefits of microservices (isolation, specialized responsibility) without the overhead of complete decoupling.
1. Ingestion Engine: Resilient Data Acquisition
The ingestion engine is significantly more sophisticated than typical ETL processes. It implements:
Progressive Enhancement: Starting with minimal viable data acquisition, then enriching as resources allow
Adaptive Retry Mechanisms: Exponential backoff with jitter to prevent thundering herd problems
Content Negotiation: Automatic handling of various compression formats and encodings
Streaming Processing: Handling data in chunks to minimize memory footprint
The key innovation here is the multi-tiered fallback system. When a data source becomes unavailable, the system doesn't just fail—it tries alternative sources, cached versions, and even synthesized datasets based on schema information.
For example, when handling CSV files, the engine employs a sophisticated encoding detection system that tries UTF-8, Latin-1, and other encodings in sequence. It uses heuristic analysis of the first few KB to determine the most likely encoding, then validates with a full schema compatibility check once loaded.
2. Staging and Transformation: Semantic Data Modeling
The staging layer transcends simple data loading by incorporating semantic understanding of the data. Rather than treating data as merely rows and columns, it:
Infers Relationships: Automatically detects primary/foreign key relationships
Normalizes on the Fly: Restructures data into dimensional models following Kimball methodologies
Tracks Data Lineage: Maintains complete provenance of all transformations
Applies Domain-Specific Rules: Uses pattern recognition to apply standard cleanings
The transformation module employs statistical analysis to identify data quality issues. It calculates column-wise statistics (distribution, outliers, null percentages) and uses these to make intelligent decisions about handling anomalies.
For categorical data, it goes beyond simple normalization by employing frequency-based encoding for high-cardinality fields and automatically extracting hierarchical relationships (e.g., city → state → country).
3. AI-Orchestrated Analysis: Beyond Simple Prompting
The analysis module represents a significant advancement in AI-orchestrated data processing:
Dynamic Chain-of-Thought Reasoning: The system doesn't just prompt an LLM once; it builds a reasoning chain where each step informs the next
Multi-Agent Collaboration: Different specialized "agents" focus on specific tasks: schema analysis, query formulation, visualization selection, and code generation
Feedback Loops: Generated code is evaluated, and errors feed back into the reasoning process
Tool Augmentation: The LLM has access to specialized tools like statistical calculators and visualization recommenders
The core innovation here is how the system handles the translation from natural language to executable code. It employs a multi-stage process:
Intent Recognition: Identifies the analysis goals (comparison, trend analysis, anomaly detection)
Schema Mapping: Maps these intents to available data attributes
Technique Selection: Chooses appropriate analytical techniques
Code Synthesis: Generates Plotly code with appropriate parameters
Validation: Tests the generated code for errors
Refinement: Iteratively improves the code based on execution results
4. Narrative Generation: Computational Storytelling
The narrative engine goes far beyond template-filling approaches to data storytelling:
Rhetorical Structure Theory: Organizes insights into coherent, goal-oriented narratives
Contrastive Explanation: Highlights what's surprising vs. expected in the data
Causal Inference: Attempts to suggest possible causal relationships (with appropriate caveats)
Audience Adaptation: Adjusts terminology and detail based on domain context
The narrative generation involves multi-hop reasoning over the visualization results. Rather than simply describing each chart individually, it synthesizes cross-cutting themes and progresses from establishing context to highlighting key relationships to suggesting possible next steps for analysis.
Technical Implementation Details
Data Flow Optimization
One of the most challenging aspects of building this system was optimizing the flow of large datasets through the pipeline. Traditional approaches often suffer from memory bottlenecks when handling datasets in the gigabyte range.
The solution involves a sophisticated buffering system that maintains "data windows" rather than loading entire datasets into memory. When operating on large CSV files, the system:
Creates a memory-mapped file for random access
Builds an index of row positions for efficient seeking
Pre-calculates column statistics using stream processing
Uses dynamic chunking based on available system resources
This approach allows processing of datasets far larger than available RAM, a critical capability for real-world analytics scenarios.
Snowflake Integration: Leveraging Cloud Data Warehousing
The integration with Snowflake demonstrates modern data engineering practices:
Dynamic Warehouse Sizing: Automatically scales compute resources based on dataset size
Zero-Copy Cloning: Creates ephemeral analysis tables without duplicating storage
Polymorphic Table Functions: Enables flexible transformations without data movement
Metadata-Driven Schemas: Automatically adapts to evolving data structures
The stage_to_snowflake function handles this complexity transparently, making decisions about table partitioning, clustering keys, and column types based on data characteristics.
LangChain Integration: Sophisticated AI Orchestration
The framework doesn't merely "call an LLM"—it implements a sophisticated orchestration layer using LangChain:
Tool-Augmented Reasoning: LLMs can invoke specialized tools when needed
Structured Output Parsing: Ensures generated code follows required patterns
Memory Management: Maintains context across multiple interactions
Agent Supervision: Implements guardrails to prevent hallucinations and invalid operations
The interaction between LangChain and Ollama (running LLaMa locally) represents a hybrid approach to AI deployment—leveraging local computation for privacy and latency while maintaining the flexibility of the LangChain ecosystem.
Visualization Rendering and Iteration
The visualization process demonstrates advanced software engineering principles:
Defensive Programming: Generated code runs in a sandboxed environment with resource limits
Progressive Enhancement: Charts are rendered with incrementally improving fidelity
Graceful Degradation: Fallback rendering paths when preferred approaches fail
Iterative Refinement: A feedback loop improves visualizations based on success metrics
The run_analysis function is particularly sophisticated in how it handles debugging and correcting errors in generated visualization code.
The User Experience: Human-Centered Data Interaction
The user interface is designed around principles of progressive disclosure and intelligent defaults. While simple in appearance, it employs sophisticated UX patterns:
Contextual Assistance: Interface elements adapt based on the current pipeline stage
Predictive Inputs: Suggests analysis approaches based on dataset characteristics
Attention Management: Directs focus to where human intervention adds most value
Cognitive Load Reduction: Abstracts complexity while maintaining transparency
The WebSocket-based update system pushes real-time status updates, showing exactly which stage of the pipeline is active:
Ingestion Stage: Displays download progress and basic dataset statistics
Staging Stage: Shows schema inference and table creation status
Transformation Stage: Highlights cleaning and normalization progress
Analysis Stage: Displays each analysis being generated with preview
Narrative Stage: Shows storytelling progress as insights are connected
Conclusion
The Prompt-to-Pipeline framework represents a fundamental rethinking of how humans interact with data. By combining sophisticated data engineering with AI agent orchestration, it creates an experience that feels magical yet produces professional-quality results.
This approach democratizes data analysis without sacrificing depth or rigor. The technical innovations in reactive processing, semantic data modeling, and computational storytelling come together to create a system that's greater than the sum of its parts.
As AI continues to advance, the boundary between human and machine contributions to data analysis will continue to evolve. This framework provides a glimpse into that future—one where humans focus on asking the right questions and interpreting results, while AI handles the technical complexity of turning those questions into answers.
I'm excited to continue developing this system and to see how it transforms how organizations derive value from their data.
Want to try Prompt-to-Pipeline with your own data?
Click here to view the github project associated with this blog: https://github.com/srinivassundar98/Prompt-to-Pipeline
For a live demo of the products capabilities, click here: https://drive.google.com/file/d/1ljO4WvnFhz9yAoo-l_9QOnv5qpu2a36t/view?usp=drive_link