InkTrace: Decoding Journalism
Our project analyzes features such as headlines, article content, and the emotions and sentiments expressed. We aim to identify unique writing styles and thematic preferences among journalists and media outlets. By developing a predictive model using deep learning techniques, we seek to ascertain the authorship of news articles. This approach will significantly enhance content personalization and provide deeper insights into media biases and reporting styles
PROJECTS
2/22/20257 min read


Motivation Behind the Project:
In a rapidly evolving digital news environment, the ability to identify the author behind an article has far-reaching implications. From uncovering media biases to refining content personalization, authorship attribution provides deeper insights into how news is shaped and presented to the public. This project addresses these needs by examining multiple facets of online news articles—headlines, full text, and the emotions and sentiments they convey—to capture each journalist’s distinctive style and thematic preferences.
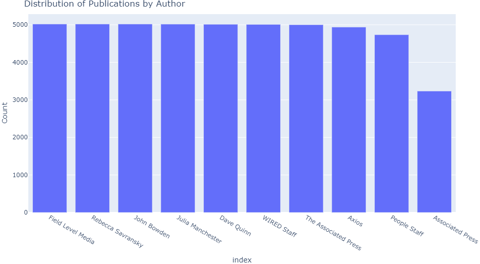
Central to our methodology is a robust data processing pipeline that sources raw data from repositories such as Kaggle, All News, All News 2.0, and The New York Times. The pipeline systematically cleans and enriches the data, applying large language models (LLMs) like RoBERTa for sentiment analysis and DistilBERT for emotion recognition. The resulting features—ranging from textual characteristics to emotional confidence scores—are then vectorized and fed into an LSTM model, enabling high-accuracy predictions of article authorship. By achieving a validation accuracy of 89% across 10 authors, this approach not only highlights the feasibility of authorship classification but also paves the way for more nuanced studies of media narratives, reporting styles, and reader engagement.
Datasets Used:
All the News Dataset: https://components.one/datasets/all-the-news-2-news-articles-dataset
The “All the News 2.0” dataset contains 2.7 million news articles and essays from 27 American publications, dating from January 1, 2016, to April 2, 2020. The raw data is formatted with fields for date, year, month, day, author, title, article text, URL, section, and publication. The dataset, updated last on July 9, 2022, is available as a CSV file and does not indicate ongoing updates beyond this point
All the News 1.0: https://components.one/datasets/all-the-news-articles-dataset
The “All the News 1.0” dataset features 204,135 articles from 18 American publications, primarily spanning from 2013 to early 2018. The data includes fields such as date, title, publication, article text, and URL, where available. It’s formatted as a SQLite database, about 1.5 GB in size, and was last updated on January 19, 2019
News Category Dataset: https://www.kaggle.com/datasets/rmisra/news-category-dataset
The News Category Dataset on Kaggle consists of around 200,000 news headlines from the year 2012 to 2018, categorized into 41 categories. Each record includes attributes like the category, headline, authors, link, and a short description. The dataset, sourced from HuffPost, is stored in JSON format and aims to facilitate news category classification and other natural language processing tasks.
Retrieval of Data:
Our project revolves around the classification of news articles based on authors and headlines. To gather the necessary data for this task, we utilized two primary sources accessed through the Python requests library and the Kaggle API:
News Category Dataset (via Kaggle API): This dataset provides a vast collection of news articles categorized into different categories. It includes metadata such as headlines, authors, publication dates, and article content. Accessed through the Kaggle API, the News Category Dataset serves as a valuable resource for training and testing our classification models based on headline and author features. We utilized the Kaggle api to write a script to get the news category dataset using an API call.
All the News Articles Dataset (via Kaggle API): Comprising a diverse range of news articles from various sources, this dataset offers extensive coverage of news topics and authors. Acquired via the Kaggle API, the All the News Articles Dataset enriches our data collection efforts by providing additional samples for training and validation. By leveraging the capabilities of the requests library and the Kaggle API, we obtained comprehensive datasets essential for our author and headline classification tasks. These datasets form the backbone of our project, enabling us to develop robust classification models and gain valuable insights into media narratives and authorship patterns.
All the News 2 News Articles Dataset The dataset consists of a diverse selection of news articles from various sources and categories. For this dataset, we directly downloaded the sqlite and csv files from the website. The dataset was then stored locally for further preprocessing and analysis as part of our project.
NYTimes Front Page Dataset For the NYTimes Front Page Dataset, we utilized the provided Dropbox link to access the dataset containing data from the front page of The New York Times newspaper. After downloading the dataset, we parsed the CSV file to extract relevant metadata fields such as headlines, publication dates, and article content. The dataset was then stored locally for preprocessing and integration into our analysis pipeline.
Extracting and Storing Datasets:
In order to manage our project’s diverse datasets effectively, we employed the pandas package to convert them into structured dataframes and subsequently saved them as CSV files. Our data retrieval process involved various methods tailored to the format of each dataset:
SQLite Database (All the News 1.0): To retrieve data from the SQLite database containing All the News 1.0, we utilized the pd.read_sql_query() method. This method allowed us to query the database directly and convert the results into a pandas dataframe.
DataFrame Creation and CSV Saving: Leveraging the capabilities of pandas, we converted the list of dictionaries into a pandas DataFrame. This DataFrame served as the foundation for our data analysis and manipulation. Finally, we saved the DataFrame as a CSV file using the to_csv() method, ensuring that the dataset is easily accessible and shareable for further analysis.
JSON Files (News Category Dataset): For datasets stored in JSON format, like the News Category Dataset, we employed the pd.read_json() method. After reading each JSON file into a dataframe, we concatenated all the dataframes into one comprehensive dataframe representing the combined dataset. This process enabled us to handle JSON data efficiently and integrate it seamlessly into our analysis pipeline.
Data Enrichment Process:
Primarily, we enrich our data by obtaining certain metrics from the current data. Our dataset is enhanced by adding additional information obtained from the existing data.
Text Summarization: For each article in our dataset, we utilize an LLM (Language Model) based text summarization method. This method condenses the content of each article into a concise summary consisting of two sentences. The resulting summaries are stored in a new column named “article_summary”.
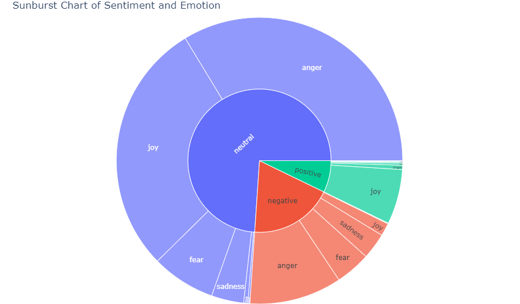
Sentiment Analysis: We employ LLMs to analyze the sentiment expressed in both the news headlines and the article summaries. -Sentiment Categories: The sentiment analysis categorizes the sentiment into three main categories: “Positive”, “Negative”, and “Neutral”. -Storing Results: The sentiment analysis results for the article summaries are stored in new columns named “article_summary_sentiment”, while the sentiment analysis results for the headlines are stored in new columns named “headline_sentiment”.
Emotion Analysis: Similarly, we utilize LLMs to analyze the emotions conveyed in both the news headlines and the article summaries. -Emotion Classes: The emotion analysis classifies emotions into six distinct classes: “Anger”, “Sadness”, “Joy”, “Surprise”, “Love”, and “Disgust”. -Storing Results: The emotion analysis results for the article summaries are stored in new columns named “article_summary_emotion”, while the emotion analysis results for the headlines are stored in new columns named “headline_emotion”.
By performing text summarization, sentiment analysis, and emotion analysis using LLMs, we enrich our dataset with valuable insights into the sentiments and emotions conveyed in the news headlines and article summaries. These enriched features provide a deeper understanding of the content and help facilitate further analysis and interpretation of the data.
Model Architecture:
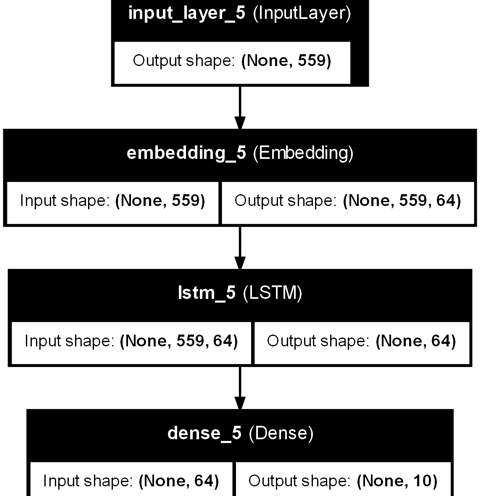
The displayed model is a Long Short-Term Memory (LSTM) network designed for multi-class text classification—specifically, to predict the author of a news article from a set of ten possible authors. Its a Keras-based architecture is organized into four primary layers:
Input Layer
Shape: (None, 559)
The None dimension corresponds to the batch size, while 559 represents the maximum sequence length (or feature dimension) of the input. Each sample is a tokenized or vectorized representation of an article’s text (which may include headline, content, sentiment, and emotion features).
Embedding Layer
Shape: (None, 559, Embedding_Dim)
This layer transforms each integer token (or feature index) into a dense, continuous vector of a specified dimension (Embedding_Dim). The goal is to capture semantic relationships between tokens, allowing the model to learn richer representations of the text data than simple one-hot encodings.
LSTM Layer
Shape: (None, 64)
The LSTM processes the sequence of embeddings, capturing contextual information and long-range dependencies within the text. By maintaining an internal memory state, the LSTM is well-suited for dealing with varying sequence lengths and complex linguistic patterns. The output here is a 64-dimensional vector summarizing the entire input sequence.
Dense Layer
Shape: (None, 10)
This final fully connected layer outputs a 10-dimensional vector—one logit per author class. A softmax activation function (not shown in the diagram but typically applied) converts these logits into probabilities for each of the 10 authors, enabling multi-class classification.
This LSTM-based architecture is dedicated to authorship attribution in news articles. The input features include:
Article Title and Content: Main textual information that captures an author’s writing style, choice of words, and thematic focus.
Sentiment Scores: Derived from a pretrained model (e.g., RoBERTa), indicating the emotional polarity (positive, negative, neutral) of the title or content.
Emotion Scores: Obtained from another pretrained model (e.g., DistilBERT), revealing specific emotional tones such as anger, joy, fear, or sadness.
By integrating these textual and emotional signals, the LSTM learns both the linguistic patterns (e.g., syntax, vocabulary) and the affective cues (e.g., tone, sentiment) that differentiate one journalist’s style from another.
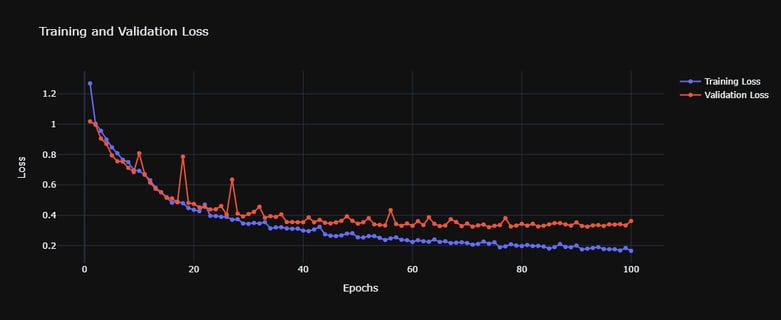
The accompanying chart shows Training Loss (blue line) and Validation Loss (red line) over 100 epochs:
Training Loss: Generally decreases in a smooth trend, indicating the model is progressively fitting the training data more accurately.
Validation Loss: Follows a similar downward trend, though with some fluctuations. This suggests the model generalizes reasonably well to unseen data, with occasional spikes likely due to mini-batch variability or momentary overfitting that quickly corrects itself.
By the final epochs, the loss values stabilize, indicating convergence. In practice, this resulted in a validation accuracy of 89% for attributing authorship among 10 different authors, underscoring the model’s effectiveness in distinguishing writing styles and thematic preferences.
For more Visualizations, click here: https://srinivassundar98.github.io/InkTrace/
For Project code, visit here: https://github.com/srinivassundar98/InkTrace