Preserving Speaker Identity In Multilingual Translation
Our project tackles a longstanding challenge in speech translation: how to accurately translate speech while retaining the original speaker’s unique vocal identity. Rather than forcing a choice between semantic accuracy and a natural, personalized voice, our integrated system achieves both—delivering translations that sound like the original speaker.
PROJECTS
2/21/20254 min read
What Are We Trying to Solve?
In conventional speech translation systems, the speaker’s identity is often lost or replaced by synthetic, impersonal voices. Our goal is to build a unified pipeline that not only converts speech from one language to another but also preserves the speaker’s individual vocal characteristics. This ensures that the emotional tone, accent, and expressiveness remain intact, making cross-lingual communication feel natural and personal.
Why It’s Important
In today’s interconnected world, effective communication goes beyond accurate language conversion. Whether for international business, remote collaboration, or personal exchanges, preserving a speaker’s voice enhances clarity and authenticity. Maintaining vocal identity:
Enhances Trust and Engagement: Listeners are more receptive when the speaker’s personality is preserved.
Supports Emotional Nuance: A natural voice carries subtle cues and emotions that synthetic voices cannot.
Enables Personalized Communication: In settings like customer service or personalized applications, retaining the speaker’s identity is essential for user satisfaction.
Architecture
Our system employs a dual-pipeline architecture that processes input speech along two parallel streams—one focused on linguistic translation and the other on voice preservation. Each stream is powered by advanced deep learning models, which are finely tuned to work in harmony:
Translation Pipeline
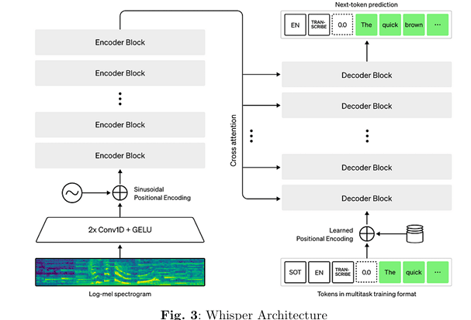
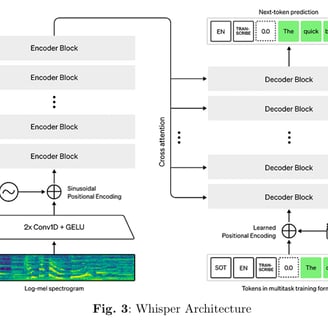
OpenAI Whisper Tiny for ASR:
Description & Architecture:
Whisper Tiny is a transformer-based Automatic Speech Recognition (ASR) model designed to balance efficiency with high transcription accuracy. It processes audio by converting raw waveforms into log-mel spectrograms using two convolutional layers with GELU activations and sinusoidal positional encoding. The spectrogram is then passed through a series of encoder blocks that generate a latent representation, which the decoder converts into text.Fine-Tuning Details:
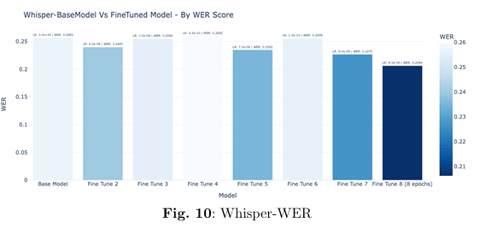
Fine-tuned on the train-clean-100 subset of the LibriSpeech dataset, the model achieved a significant reduction in Word Error Rate (WER) from 0.2569 to 0.2064 and Character Error Rate (CER) from 0.0698 to 0.0573—improving its real-time transcription performance.
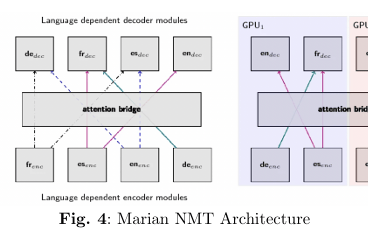
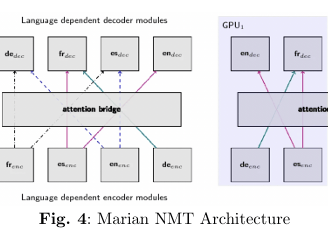
MarianMT for Neural Machine Translation (NMT):
Description & Architecture:
MarianMT utilizes a robust encoder–decoder framework with dynamic attention mechanisms. Each input language is processed by language-specific encoders and decoders, which are interconnected through an attention bridge. This modular design supports efficient multi-GPU processing and ensures that context is preserved during translation.Fine-Tuning Details:
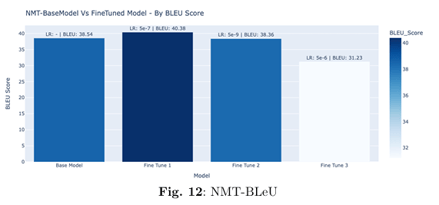
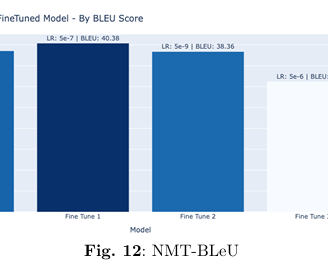
Fine-tuned on the OPUS dataset containing high-quality parallel sentences, MarianMT’s BLEU score improved from 38.54 to 40.38—demonstrating enhanced translation accuracy, particularly for English-to-French conversions.
Voice Preservation Pipeline
XTTS V2 for Voice Synthesis and Cloning:
Description & Architecture:
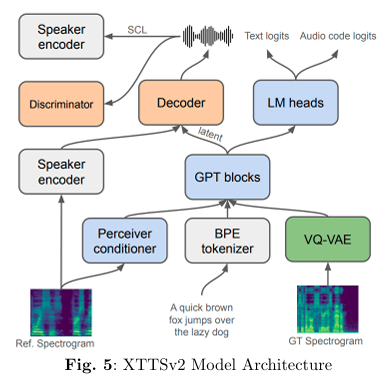
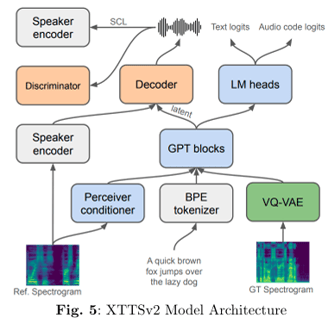
XTTS V2 is a multilingual text-to-speech system engineered for natural-sounding voice synthesis and precise voice cloning. The architecture begins with BPE tokenization of the input text, followed by a Perceiver conditioner that integrates contextual information. GPT blocks then generate latent representations, which are transformed into high-quality spectrograms by a VQ-VAE module. A dedicated Speaker Encoder ensures that the generated audio faithfully reproduces the original speaker’s vocal characteristics.Fine-Tuning Details:
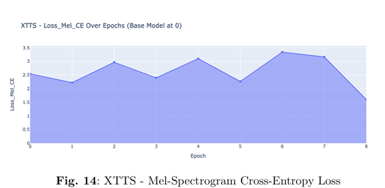
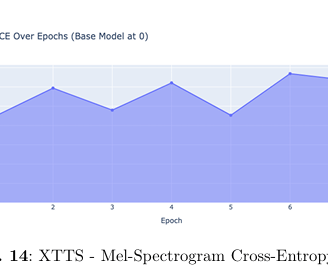
Using the Mozilla Common Voice French dataset, XTTS V2 was fine-tuned to significantly reduce both Text Cross-Entropy and Mel Cepstral Error (Mel CE loss), resulting in more natural and expressive synthesized speech.
HiFiGAN for High-Fidelity Audio Synthesis:
Description & Role in the Pipeline:
HiFiGAN is a cutting-edge generative adversarial network designed for high-fidelity audio synthesis. In our system, it is integrated as a post-processing module to refine the audio quality of the synthesized speech from XTTS V2.Usage Note:
Although HiFiGAN was used to enhance the naturalness and clarity of the output, it was incorporated in its pre-trained form and not subjected to additional fine-tuning.
Datasets Used
LibriSpeech: Employed for fine-tuning the ASR component (Whisper Tiny), providing diverse and high-quality speech data.
OPUS: Utilized for training the neural machine translation model (MarianMT) with extensive parallel sentences.
Mozilla Common Voice (French): Used to fine-tune XTTS V2, ensuring accurate and natural French voice synthesis.
Evaluation Metrics
ASR (Whisper Tiny): Evaluated using Word Error Rate (WER) and Character Error Rate (CER).
Translation (MarianMT): Assessed by the BLEU score.
Voice Synthesis (XTTS V2): Measured using Mel Cepstral Error (Mel CE loss) along with Text Cross-Entropy loss.
Results
The fine-tuning process yielded significant improvements across all components of the speech translation system. The Whisper ASR model demonstrated a 19.7% improve ment in WER (from 0.2569 to 0.2064) and an 18% reduction in CER (from 0.0698 to 0.0573), indicating substantial enhancement in transcription accuracy.
The MarianMT component achieved a 4.8% improvement in BLEU score, increasing from 38.54 to 40.38, reflecting better translation quality.
The XTTS voice synthesis model showed notable improvements across multiple metrics from the base model (epoch 0) to the final fine-tuned version: Text CE loss decreased by 18.5% (0.027 to 0.022), Mel CE loss improved by 36% (2.5 to 1.6), and total loss showed a significant 66.7% reduction (0.03 to 0.01), indicating substantial enhancement in voice synthesis quality.
To view other results including cases where the Whisper and Marian NMT fine-tuned models outperformed their base counterparts, click here.
Looking forward, several avenues for enhancement present themselves. A more personalized approach could involve fine-tuning both ASR and voice cloning models using user specific data, potentially creating more accurate and natural-sounding translations for individual users. Additionally, the translation component could be further enhanced by fine-tuning with domain-specific datasets, addressing specialized vocabulary and conventions in fields like healthcare, legal, or business sectors. This targeted approach would help address the current challenges in translating technical terminology and industry-specific nomenclature.
The code for this project can be found here: https://github.com/srinivassundar98/Preserving-Speaker-Identity-In-Multilingual-Translation
The report for this project can be found here: https://github.com/srinivassundar98/Preserving-Speaker-Identity-In-Multilingual-Translation/blob/main/Preserving-Speaker-Identity.pdf
More results can be viewed here: https://srinivassundar98.github.io/Preserving-Speaker-Identity-In-Multilingual-Translation/