Tri-Database: A Multi-Database Architecture with Unique Cache Handling for Real-Time Data Management
This project describes the development of a tri-database architecture designed for effective management and querying of Twitter data by integrating Snowflake, MySQL, and MongoDB to optimize storage for both user and tweet information. A Python-driven data ingestion system, combined with Kafka for simulating real-time streaming, lays the foundation for the pipeline, while an intelligent indexing mechanism significantly accelerates data retrieval. The search application, built with Streamlit, provides comprehensive query options along with advanced drill-down features, and a multi-layered caching strategy further boosts system performance. Performance evaluations using test queries confirm the system's efficiency and illustrate how architectural decisions impact response times and data relevance.
PROJECTS
5/8/202410 min read
Introduction
The advent of social media has resulted in an explosive growth of data generation, with platforms like Twitter leading the charge. Twitter's user base generates a staggering volume of content each second, offering invaluable insights into public sentiment, market dynamics, and unfolding events. However, this wealth of data presents significant challenges in terms of storage, processing, and retrieval. Traditional data management solutions are often inadequate for handling the variety, velocity, and volume of Twitter data.
This report underscores the essential requirement for effective and scalable architectural solutions capable of storing, processing, and analyzing Twitter data streams in real-time. It investigates cutting-edge methodologies designed to handle the extensive quantities of data and support intelligent querying and retrieval processes that yield timely, actionable insights within a search application. The convergence of sophisticated data processing frameworks and advanced search functionalities is proposed to ensure a comprehensive solution adept at managing the complexity and expansiveness of Twitter data flows.
The discourse extends to the integration of distributed storage systems with refined data processing pipelines. This examination seeks to determine the orchestration necessary to enhance both performance and dependability. The ambition is to establish a formidable architecture that promotes the swift intake of high-volume Twitter data, implements effective storage strategies for expedited access and analysis, and introduces search applications that facilitate pertinent and user-friendly data navigation.
Employing innovative big data technologies and search algorithms, the proposed solution endeavors to reconcile the exigencies of rapid processing with the analytical depth required for thorough data examination. The architecture is not only tailored for the efficient capture and storage of Twitter data but also for distilling significant patterns, tracking sentiment evolution, and promptly responding to the derived insights. Additionally, the integration of machine learning models such as sentiment analysis, emotion detection, and topic modeling enrich the understanding of the data corpus.
Dataset:
The core of the dataset is the tweet itself, which relates to topics around Corona. This information is paired with extensive metadata about the user who posted it, including their profile, follower statistics, and account details, providing context about the tweeter's social influence and credibility. The dataset also includes engagement metrics such as the number of retweets, replies, and favorites, which help gauge the tweet's reach and audience interaction. Additionally, it contains geographical data pinpointing where the tweet was posted, which can be vital for geospatial analyses of social media trends. This dataset is valuable for a variety of applications, including sentiment analysis, trend tracking, and demographic studies, offering insights into public perception and social media dynamics during the specified period.
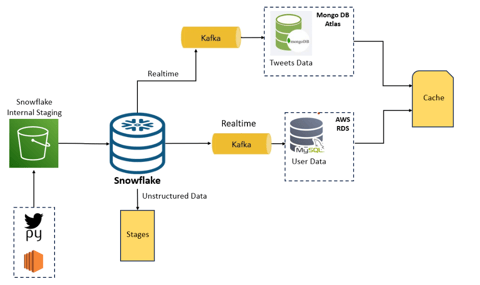
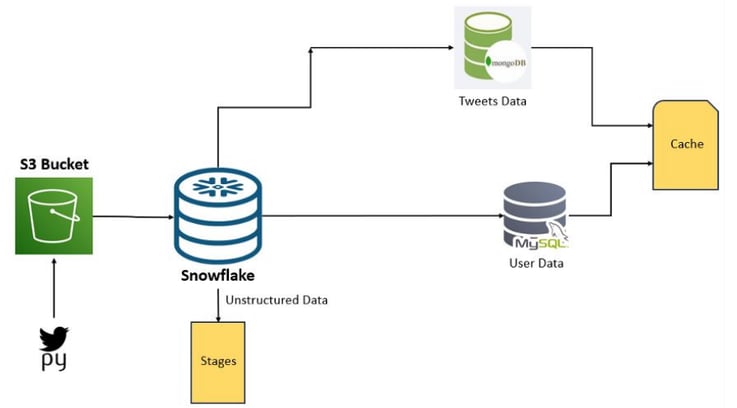
Overall Architecture:
DATA INGESTION PROCESS:
A Python script is utilized to process the Twitter dataset. This script is scheduled to run periodically using CronJob, that is new data is ingested into the system hourly. The Python script processes the data and outputs it as JSON files. The data is being converted into JSON, format suitable for transmission or storage that supports hierarchical structures. These JSON files are then sent to Snowflake's internal staging area. Staging areas are temporary storage spaces where data can be held before it is loaded into the data warehouse. Snowflake is a cloud-based data platform that offers data warehousing capabilities. Within Snowflake, the data is stored in a staging table designed for semi-structured data. Semi-structured data is a form of data that does not conform to the tabular structure associated with relational databases but has some organizational properties that make it easier to analyse than unstructured data. Finally, the data from the staging table is moved to raw tables. Raw tables in a data warehouse are used for the initial storage of ingested data before it undergoes further processing or is moved to other tables for specific analytic purposes.
DATA TRANSFORMATION PIPELINE
The Tweets, Retweets and User Tables are the raw tables that are obtained from the previously discussed step in snowflake. This is the data from the source and contains unprocessed data in a structured format. This data may be inconsistent, contain errors, or missing data that are not immediately suitable for analysis.
Clean/Preprocess the Data: The next step involves cleaning and preprocessing the data. This is a crucial step in any data pipeline and it involves removing or correcting inaccuracies, dealing with missing values, and performing other data quality improvements to ensure the data is in a usable state for analysis.
Translate Tweets to English: Since the raw data includes tweets and retweets that are in various languages, this step involves translating them into English using the translator imported from googletrans module. This standardization is important for consistent analysis, especially when employing natural language processing techniques.
After the data has been cleaned and standardized, it moves on to the machine learning pipeline, which consists of:
· Topic Modelling: This analysis aims to identify the underlying themes or topics within the corpus of tweets. Topic modelling is an NLP task that discovers abstract topics within text, helping to understand the main subjects discussed across the tweets.
· Sentiment Analysis: Here, the pipeline includes an analysis to discern the sentiment behind each tweet—whether the emotions expressed are positive, negative, or neutral. This involves using pre-trained models to classify sentiment based on the text.
· Emotion Detection: This step goes beyond sentiment analysis by identifying specific emotions conveyed in the tweets, such as joy, anger, or sadness. This can add depth to the analysis by providing insights into the emotional responses associated with different topics or events.
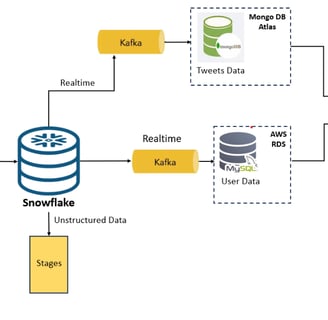
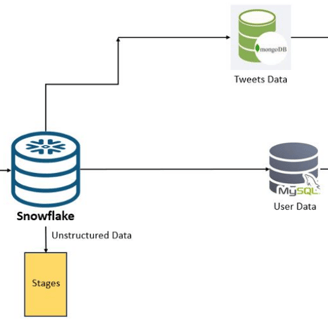
SNOWFLAKE EGRESS
The methodology for data egress encompasses the migration or exportation of datasets from Snowflake to designated storage solutions, specifically MySQL and MongoDB databases. This process utilizes Amazon EC2 instances as intermediate agents, leveraging their scalable compute capacity in the cloud to facilitate a secure data transfer.
The strategic plan includes the integration of a Kafka pipeline, an advanced distributed event streaming platform renowned for its ability to manage substantial data volumes. The implementation of Kafka is anticipated to substantially augment the real-time data processing capabilities of the current architecture—a critical component for maintaining up-to-the-minute data flows.
Upon the successful implementation of this system, user-related information is earmarked for storage in the MySQL database, while tweets and retweets are allocated to MongoDB. Each database is hosted on its respective cloud service—AWS RDS for MySQL and MongoDB Atlas for MongoDB—ensuring reliable and scalable cloud support.
Complementing the storage architecture is a caching mechanism paired with the search application. This addition is engineered to optimize data retrieval speeds, effectively bolstering the performance and responsiveness of the system.
Indexing:
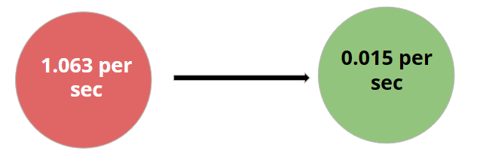
A query optimization on the MySQL is done using indexing for enhancing user data retrieval. The results are queried almost 70 times faster post using indexing.
Caching:
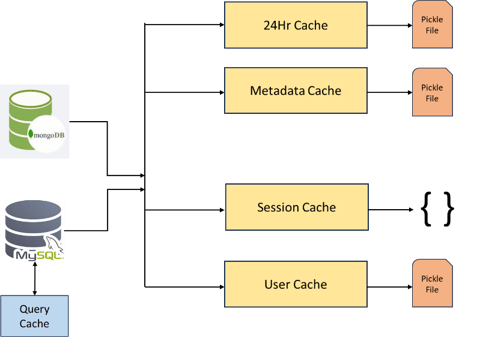
In the system implemented, caching plays a crucial role in enhancing performance by allowing for the rapid retrieval of frequently accessed data, effectively reducing the need to repeatedly read from disk. To cater to the diverse needs of data access and retrieval, a multi-faceted caching approach has been implemented that includes session caching, a 24-hour result cache, and summary-statistic cache.
Session caching is designed to be compact, with a typical size ranging from 5 to 10MB. This cache is ephemeral, existing only for the duration of a user session, and is cleared once the session is terminated. An LRU eviction policy is employed to manage the cache's limited capacity, where the least recently accessed items are discarded first. This mechanism ensures that active session data is retrieved swiftly and is stored using a dictionary format within the cache for efficient access and modification.
The 24-hour result cache, as indicated by its name, stores items with a TTL of 24 hours. After this period, the data is deemed expired and is eligible for automated purging. The removal of outdated items is handled by a dedicated method, which cleanses the cache of stale entries. Should the cache reach its maximum capacity, it adheres to the LRU policy to make room for new data, prioritizing the retention of recently accessed items.
For data that sees frequent consumption, such as the most active users or the highest number of retweets, we implement summary-statistic caching. The unique aspect of this caching strategy is its persistent nature, achieved by serializing JSON objects into a pickle file. This persistence ensures that there is no loss of cache state between program executions, thereby providing quick access to popular data without the need to regenerate or refetch it. The use of `OrderedDict` is common across all our caching techniques, maintaining the order of data insertion and facilitating the LRU eviction policy by keeping track of which items to discard first as new data comes in.
Together, these three caching strategies form a comprehensive system that delivers fast, reliable data access tailored to the specific temporal and operational requirements of our application, thereby ensuring optimal performance with minimal delays. It is aimed to enhance the caching mechanism by establishing a user cache that anticipates and preloads pertinent data based on insights obtained from user activity logs from the application.
Search Application Design:
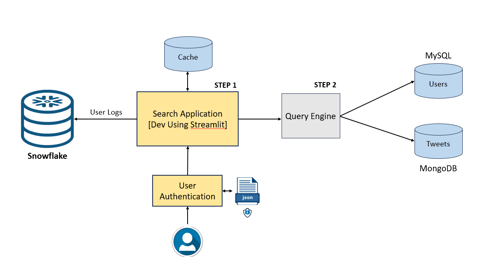
The search application is constructed utilizing Streamlit, an open-source application framework. The initial stage of user interaction with the application is underpinned by a robust user authentication system. This system secures the application by requiring users to log in with valid credentials, which are meticulously verified to prevent unauthorized access.
Data retrieval, a critical functionality within the application, is executed in two distinct phases. Primarily, the application seeks to retrieve the required data from a strategically implemented cache. This caching mechanism substantially accelerates data access, thereby curtailing the frequency of database queries. This not only enhances performance by diminishing load times but also elevates the overall user experience. When data requests are fulfilled from the cache, the frontend operations proceed without delay.
In instances where the cache does not contain the requested data, the backend comes into play, powered by a query engine that processes the application's search queries. This engine is integral to the application, equipped with business logic capable of deciphering user queries and procuring the appropriate data. The user-related information is stored within a MySQL database, while tweet and retweet data are housed in MongoDB. The query engine effectively liaises with both databases, procuring data as necessitated by user-initiated searches or specific commands.
Additionally, Snowflake is employed to maintain user logs that chronicle the spectrum of user activities and interactions with the application. Collectively, the components of the search application function in concert to deliver a streamlined and intuitive user interface, maintaining high standards of data management and security protocols.
The search application interface is tailored for the twitter data analysis. The application allows for a variety of search and analysis types. Also, the navigation panel on the left provides a simple and intuitive method for switching between different types of analysis. Different search tabs are -
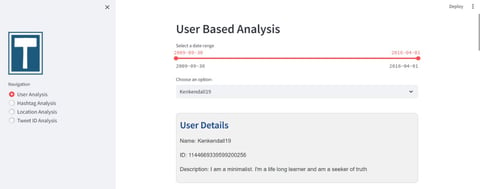
· User Analysis: Users can search for specific Twitter users to gather detailed analytics. The 'User Details' demonstrates that once a user is selected, details such as username, ID, and their self-description are displayed.
· Hashtag Analysis: This feature enables users to search and track the usage and popularity of specific hashtags over time, which can be critical for understanding trends and the spread of information or campaigns on social media.
· Location Analysis: This function allows users to search and analyze tweets based on location data, which can be useful for geo-targeted marketing, understanding regional discourse, and more.
· Tweet ID Analysis: By analyzing specific tweet IDs, users can drill down into individual tweets to understand engagement, reach, and the tweet's content for closer examination.
Another drill down feature is that while selecting either a user or tweet id or hashtag is that one can select a date range, providing the ability to analyse activity within specified timeframes.
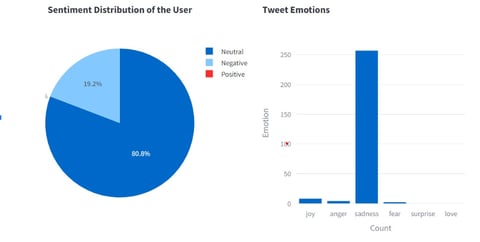
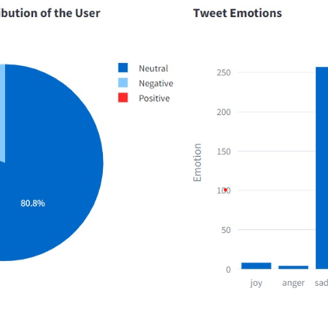
The drill-down capability is noticed in all the 4 panels. For instance, selecting a user allows for drilling down into their tweet history (most popular tweets), retweet patterns (Top 10 retweets), sentiment of the tweets, user interaction over time, and other engagement metrics.
Conclusion:
The Twitter Data Search application has been built from scratch and stands as a comprehensive tool for managing and exploring Twitter data. This powerful application boasts advanced drill-down features that significantly boost its data analysis capabilities. It offers an array of visual analytics, including insights into the top 10 most retweeted posts, evaluations of the most popular tweets, and detailed analyses of the sentiments and emotions conveyed in the tweets. Moreover, the tool performs thematic analyses to uncover dominant topics, providing a deeper understanding of content trends and the spread of information across social media platforms. It also incorporates location analysis, which delivers valuable strategic insights for geo-targeted marketing and a nuanced understanding of regional communication patterns.
In evaluating our project, we recognize several limitations within the current framework. The system's complexity in maintenance and monitoring could potentially hinder its long-term manageability. Additionally, the application lacks real-time data processing capabilities and does not yet include a robust authentication system, which is crucial for ensuring enhanced security and controlled access. Furthermore, the absence of multithreading in our caching mechanism limits performance optimization. These shortcomings highlight clear avenues for future improvements and reinforce our commitment to continuous enhancement.
Looking ahead, we plan to incorporate Kafka to enable true real-time data streaming, and we are exploring an enhanced caching strategy that leverages historical user logs to further boost system performance. We also aim to implement a more secure authentication system along with multithreading for our four caching strategies. These forthcoming advancements are designed to strengthen the application's overall efficiency and its ability to deliver rapid, data-driven insights.
To view the code, click here:https://github.com/srinivassundar98/TRIUNE-DATABASE-A-Multi-Database-Architecture/
To view a mock demo, click here: https://multi-database-architecture.streamlit.app/
To look at the Data Pipeline, click here: https://srinivassundar98.github.io/TRIUNE-DATABASE-A-Multi-Database-Architecture/